邻接表
邻接矩阵是不错的一种图存储结构,但是,对于边数相对顶点较少的图,这种结构存在对存储空间的极大浪费。因此,找到一种数组与链表相结合的存储方法称为邻接表。
邻接表的处理方法是这样的:
(1)图中顶点用一个一维数组存储,当然,顶点也可以用单链表来存储,不过,数组可以较容易的读取顶点的信息,更加方便。
(2)图中每个顶点vi的所有邻接点构成一个线性表,由于邻接点的个数不定,所以,用单链表存储,无向图称为顶点vi的边表,有向图则称为顶点vi作为弧尾的出边表。
例如,下图就是一个无向图的邻接表的结构。
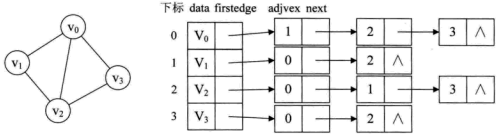
从图中可以看出,顶点表的各个结点由data和firstedge两个域表示,data是数据域,存储顶点的信息,firstedge是指针域,指向边表的第一个结点,即此顶点的第一个邻接点。边表结点由adjvex和next两个域组成。adjvex是邻接点域,存储某顶点的邻接点在顶点表中的下标,next则存储指向边表中下一个结点的指针。
对于带权值的网图,可以在边表结点定义中再增加一个weight的数据域,存储权值信息即可。如下图所示。
邻结矩阵和邻接表的区别
对于一个具有n个顶点e条边的无向图
它的邻接表表示有n个顶点表结点2e个边表结点
对于一个具有n个顶点e条边的有向图
它的邻接表表示有n个顶点表结点e个边表结点
如果图中边的数目远远小于n2称作稀疏图,这时用邻接表表示比用邻接矩阵表示节省空间;
如果图中边的数目接近于n2,对于无向图接近于n*(n-1)称作稠密图,考虑到邻接表中要附加链域,采用邻接矩阵表示法为宜。
参考代码
#include <stdio.h>
#include <string.h>
struct node {
int to, next, val;
}edge[100005];//边的数量100005
int head[1005];//点的数量1005
int k;
void init() {//初始化
k = 0;
memset(head, -1, sizeof(head));
}
void add(int x, int y, int val) {//加边操作
edge[k].to = y;
edge[k].val = val;
edge[k].next = head[x];
head[x] = k++;
}
int main() {
int n, m;
scanf("%d%d", &n, &m);
init();
int a, b, c;
for(int i = 1; i <= m; i++) {
scanf("%d%d%d", &a, &b, &c);
add(a, b, c);//加入有向边a->b权值为c
add(b, a, c);
}
return 0;
}
掌握本节内容


 The road of your choice, you have to go on !
粤ICP备16082171号-1
The road of your choice, you have to go on !
粤ICP备16082171号-1



登录后开始许愿
暂无评论,来抢沙发