
科目组合
计算机: 数据结构 、计算机组成原理 、操作系统 、计算机网络
答题情况分析报告

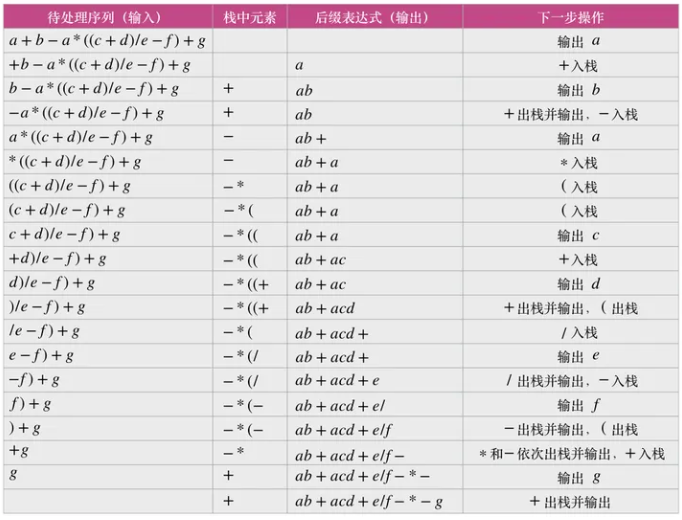


对如下有向图带权图,若采用迪杰斯特拉(Dijkstra)算法求从源点a到其他各顶点的最短路径,则得到的第一条最短路径的目标顶点是b,第二条最短路径的目标顶点是c,后续得到的其余最短路径的目标顶点依次是( )。

A. d, e, f
B. e, d, f
C. f, d, e
D. f, e, d







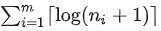 位,其中 m 表示互斥类数量, ni 表示第 i 个互斥类的微命令数量,本题有5个互斥类,分别包含7、3、12、5和6个微命令,计算结果为 ⌈log(7+1)⌉+⌈log(3+1)⌉+⌈log(12+1)⌉+⌈log(5+1)⌉+⌈log(6+1)⌉=15 。
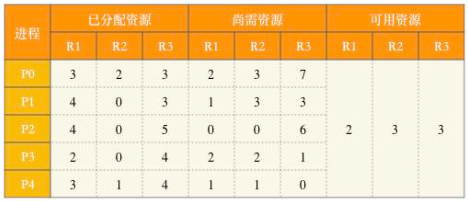
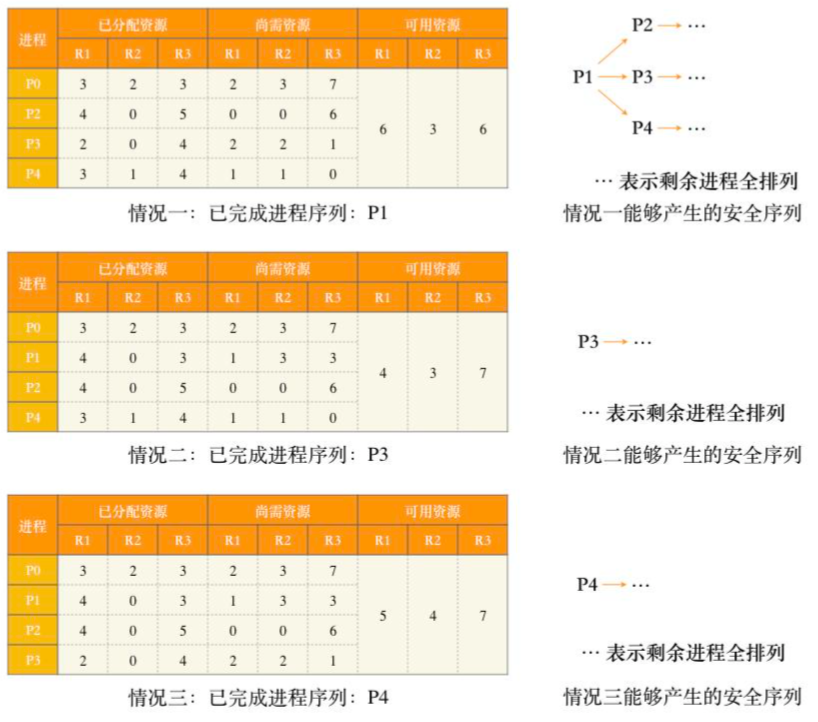
位,其中 m 表示互斥类数量, ni 表示第 i 个互斥类的微命令数量,本题有5个互斥类,分别包含7、3、12、5和6个微命令,计算结果为 ⌈log(7+1)⌉+⌈log(3+1)⌉+⌈log(12+1)⌉+⌈log(5+1)⌉+⌈log(6+1)⌉=15 。假设5个进程P0、P1、P2、P3、P4共享三类资源R1、R2、R3,这些资源总数分别为18、6、22。T0时刻的资源分配情况如下表所示,此时存在的一个安全序列是( )。
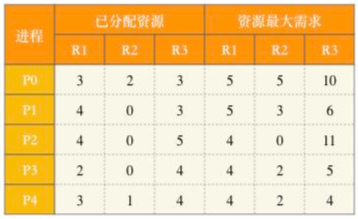
A. P0, P2, P4, P1, P3
B. P1, P0, P3, P4, P2
C. P2, P1, P0, P3, P4
D. P3, P4, P2, P1, P0
若用户1与用户2之间发送和接收电子邮件的过程如下图所示,则图中 ①、②、③ 阶段分别使用的应用层协议可以是
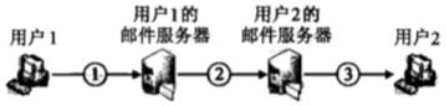
A. SMTP、SMTP、SMTP
B. POP3、SMTP、POP3
C. POP3、SMTP、SMTP
D. SMTP、SMTP、POP3
-
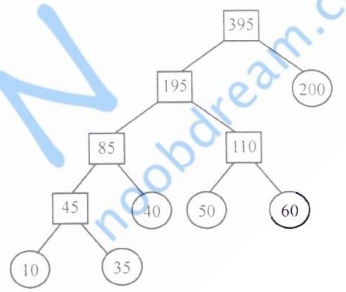
最坏情况下比较的总次数为
(10+35-1) + (10+35-1+40-1) + (10+35-1+40-1+50-1) + (10+35-1+40-1+50-1+60-1) + (10+35-1+40-1+50-1+60-1+200-1) = 44 + 84 + 109 + 194 + 394 = WPL - 5 = (40 + 50 + 60) * 3 + 200 * 1 + (10+35) * 4 - 5 = 825比较过程如下
```mermaid flowchart TD Root["Total (395; cp:394)"] A["A (10)"] B["B (35)"] C["C (40)"] D["D (50)"] E["E (60)"] F["F (200)"] L1["A+B (45; cp44)"] L2["A+B+C (85; cp84)"] L3["D+E (110; cp109)"] L4["A+B+C+D+E (195; cp194)"] Root-->F Root-->L4 L4-->L2 L4-->L3 L3-->D L3-->E L2-->L1 L2-->C L1-->A L1-->B```
-
在对多个有序表进行两两合并时,若表长不同,则最坏情况下总的比较次数依赖于表的合并次序。可以借用哈夫曼树的构造思想,依次选择最短的两个表进行合并,可以获得最坏情况下最佳的合并效率
评分及理由
(1)得分及理由(满分7分)
学生给出了完整的合并过程,采用了哈夫曼树(最佳归并树)的思想,合并顺序正确:先合并A(10)和B(35)得到AB(45),再合并AB(45)和C(40)得到ABC(85),然后合并D(50)和E(60)得到DE(110),接着合并ABC(85)和DE(110)得到ABCDE(195),最后合并ABCDE(195)和F(200)得到最终表。这个过程与标准答案一致。
最坏情况下比较次数的计算也正确:
- A+B: 10+35-1=44
- AB+C: 45+40-1=84
- D+E: 50+60-1=109
- ABC+DE: 85+110-1=194
- ABCDE+F: 195+200-1=394
- 总计:44+84+109+194+394=825
学生还提供了WPL计算的验证方法,虽然这不是必需的,但思路正确。因此,本小题得7分。
(2)得分及理由(满分3分)
学生准确描述了合并策略:采用哈夫曼树构造思想,依次选择最短的两个表进行合并,以获得最坏情况下最佳的合并效率。这与标准答案完全一致,描述清晰准确。因此,本小题得3分。
题目总分:7+3=10分
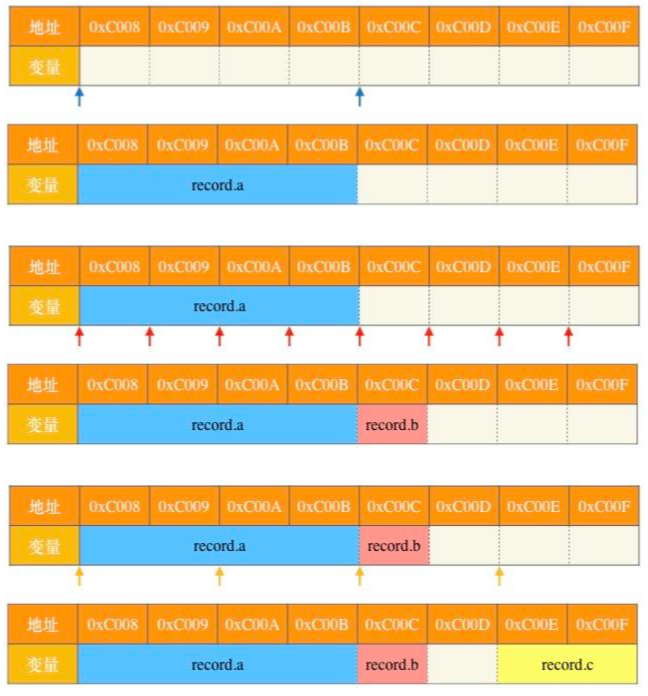
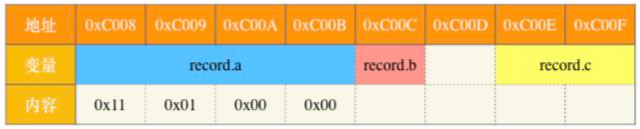
(13分)假定采用带头结点的单链表保存单词,当两个单词有相同的后缀时,则可共享相同的后缀存储空间,例如,’loading’和’being’的存储映像如下图所示。
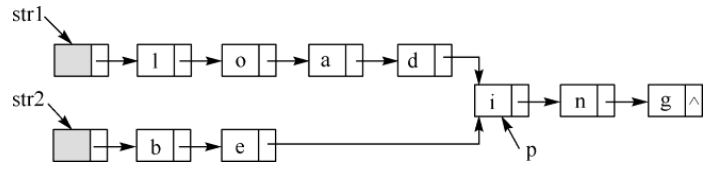
设str1和str2分别指向两个单词所在单链表的头结点,链表结点结构为 datanext ,请设计一个时间上尽可能高效的算法,找出由str1和str2所指向两个链表共同后缀的起始位置(如图中字符i所在的结点位置p)。要求:
⑴ 给出算法的基本设计思想。(4分)
⑵ 根据设计思想,采用C或C++或Java语言描述算法,关键之处给出注释。(8分)
⑶ 说明你所设计算法的时间复杂度。(1分)
1. 查找两个单链表的第一个公共节点;head1、head2为两个链表的头指针;返回第一个公共节点的指针,如果没有公共节点则返回NULL
2.
Node* findCommon(Node *head1, Node *head2){
Node* current1 = head1;
Node* current2 = head2;
int len1 = 0, len2 = 0;
// 计算链表1长度
while (current1 != NULL){
len1++;
current1 = current1->next;
}
// 计算链表2长度
while (current2 != NULL){
len2++;
current2 = current2->next;
}
// 重新指向头结点
current1 = head1;
current2 = head2;
// 让较长的链表先走差值步
while (len1 > len2){
current1 = current1->next;
len1--;
}
while(len1 < len2){
current2 = current2->next;
len2--;
}
// 同步向后遍历,直到遇到公共节点或到末尾
while(current1 != NULL && current1 != current2){
current1 = current1->next;
current2 = current2->next;
}
return (current1 == current2)?current1:NULL;
}
3. 时间复杂度为 O(m+n)
评分及理由
(1)得分及理由(满分4分)
得分:4分
理由:学生给出的算法基本设计思想正确,明确说明了通过计算两个链表长度,让较长的链表先走差值步,然后同步遍历找到第一个公共节点。这与标准答案的思路完全一致,表述清晰。
(2)得分及理由(满分8分)
得分:7分
理由:算法实现基本正确,但存在一个逻辑错误:题目要求是带头结点的单链表,但学生的代码中current1和current2初始指向的是head1和head2,在带头结点的情况下,头结点不存储数据,应该从head1->next和head2->next开始计算长度和遍历。这个错误导致算法在实际带头结点的链表上无法正确工作。其他部分逻辑正确,代码结构清晰,注释适当。
(3)得分及理由(满分1分)
得分:1分
理由:学生正确分析了算法的时间复杂度为O(m+n),与标准答案一致。
题目总分:4+7+1=12分
-
MIPS数为20;
Cache缺失次数 = 2 \times 10^{7} \times 1.5 \times (100\%-99\%) = 3 \times 10^{5}次;
带宽 = 3 \times 10^{5}次 \times 16B/s = 48 \times 10^{5}B/s = 4.8MB/s
-
每秒的缺页异常次数 = 3 \times 10^{5}次 \times \frac{0.0005}{100} = 1.5次/s;
每秒缺页时需要读入的数据量 = 1.5次/s \times 4KB = 6KB/s;
磁盘I/O接口平均每秒发出的DMA请求次数 = \frac{6 \times 2^{10}B \times 8B/bit}{32bit} = 1.5 \times 2^{10} = 1536次
-
DMA优先级比CPU更高,因为DMA传输数据时,数据会往接口里面的端口准备数据,要尽快取出数据,否则可能会出现数据覆盖
-
带宽 = \frac{32b \times 4}{50ns} = 3.2 \times 10^{8}MB/s
评分及理由
(1)得分及理由(满分4分)
学生答案中:
- MIPS数计算正确,得1分。
- Cache缺失次数计算正确(虽然写法是3×10^5,但数值正确),得1分。
- 主存带宽计算正确(4.8MB/s),得2分。
本小题得4分。
(2)得分及理由(满分2分)
学生答案中:
- 缺页异常次数计算正确(1.5次/s),得1分。
- DMA请求次数计算过程有误(公式中出现了“8B/bit”的错误单位,但最终结果1536正确),因为结果正确且主要思路正确,不扣分,得1分。
本小题得2分。
(3)得分及理由(满分2分)
学生答案中:
- 正确指出DMA优先级更高,得1分。
- 理由描述基本正确(数据需要及时取出避免覆盖),得1分。
本小题得2分。
(4)得分及理由(满分2分)
学生答案中:
- 计算过程有误:公式中“32b”应为“32位=4B”,且结果单位错误(写成了MB/s,应为B/s或转换后的MB/s),数值3.2×10^8错误(正确应为320MB/s即3.2×10^8 B/s)。
- 但思路正确(考虑四体交叉和存储周期),给1分。
本小题得1分。
题目总分:4+2+2+1=9分
(13分)某16位计算机中,带符号整数用补码表示,数据Cache和指令Cache分离。下表给出了指令系统中部分指令格式,其中Rs和Rd表示寄存器,mem表示存储单元地址,(x)表示寄存器x或存储单元x的内容。

该计算机采用5段流水方式执行指令,各流水段分别是取指(IF)、译码/读寄存器(ID)、执行/计算有效地址(EX)、访问存储器(M)和结果写回寄存器(WB),流水线采用“按序发射,按序完成”方式,没有采用转发技术处理数据相关,并且同一个寄存器的读和写操作不能在同一个时钟周期内进行。请回答下列问题:
(1) 若int型变量x的值为-513,存放在寄存器R1中,则执行指令“SHR R1” 后,R1的内容是多少(用十六进制表示)?(2分)
(2) 若某个时间段中,有连续的4条指令进入流水线,在其执行过程中没有发生任何阻塞,则执行这4条指令所需的时钟周期数为多少?(2分)
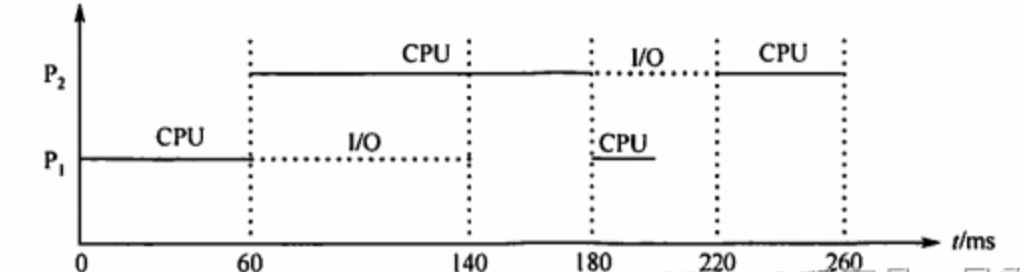
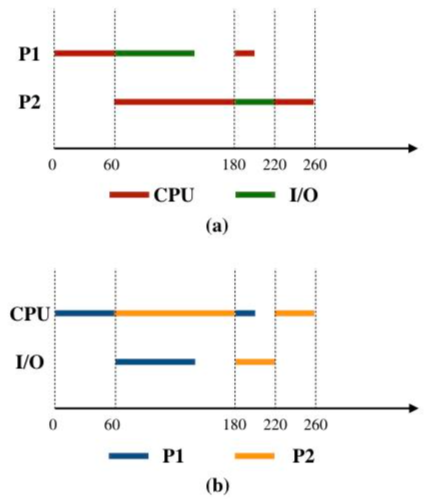
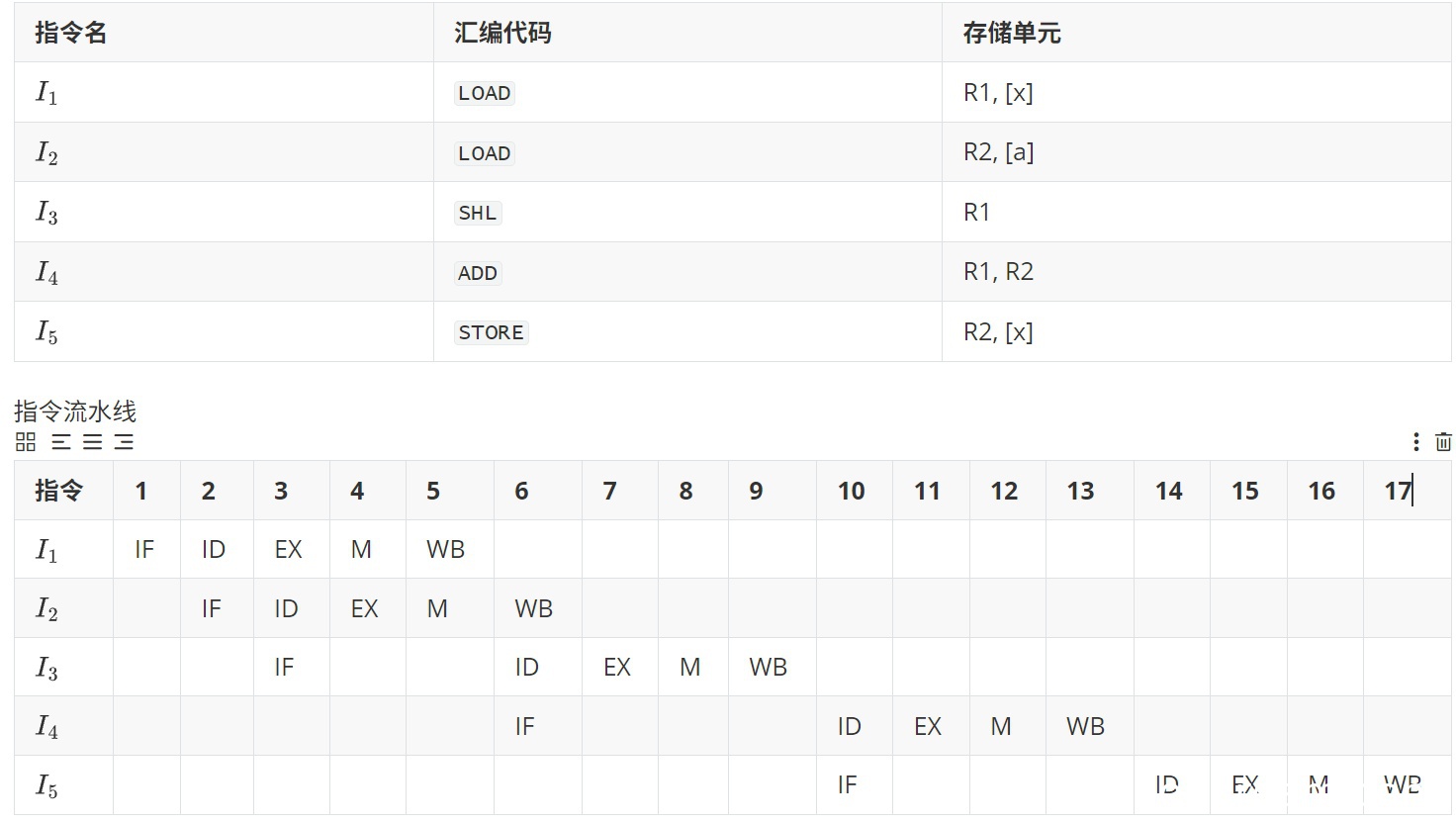
(3) 若高级语言程序中某赋值语句为x=a+b,x、a和b均为int型变量,它们的存储单元地址分别表示为[x]、[a]和[b]。该语句对应的指令序列及其在指令流水线中的执行过程如下图所示。

则这4条指令执行过程中,I3的ID段和I4的IF段被阻塞的原因各是什么?(2分)
(4) 若高级语言程序中某赋值语句为x=x*2+a,x和a均为unsigned int类型变量,它们的存储单元地址分别表示为[x]、[a],则执行这条语句至少需要多少个时钟周期?要求模仿题44图画出这条语句对应的指令序列及其在流水线中的执行过程示意图。(7分)
-
$$的原码格式为
1000 0000 0000 0000 0000 0010 0000 0001b,补码为`1111 1111 1111 1111 1111 1101 1111 1111b` 也就是FFFF FDFFH,舍去高 16 位,得FDFFH;执行指令“SHR R1”后,R1变成1111 1111 1111 1111 1111 1110 1111 1111b也就是FFFF FEFFH,舍去高 16 位,得FEFFH -
执行这4条指令所需的时钟周期数为
(5 + 4 - 1) = 8 -
因为 I3 与 “I1 和 I2“ 都存在数据冒险,需等到 I1 和 I2 将结果写回寄存器后,I3 才能读寄存器内容,所以 I3 段的
ID阻塞了两个时钟周期;因为 I4 的前一条指令 I3 在 ID 段被阻塞,I3 还没来得及锁寄存器IR,流水段寄存器的数据尚未取完,倘若此时 I4 要执行IF,那么 I3 拿到的是 I4 的译码结果,会覆盖 I3 的指令,所以 I4 的IF段被阻塞 -
至少需要 17 个时钟周期,如下
评分及理由
(1)得分及理由(满分2分)
学生答案中正确给出了执行指令后R1的内容为FEFFH,且计算过程正确(从FDFFH右移得到FEFFH)。虽然原码和补码的表示部分存在冗余信息(如32位表示),但核心结果正确。根据标准答案,正确写出结果即可得满分。
得分:2分
(2)得分及理由(满分2分)
学生答案正确计算了4条指令在5段流水线中所需时钟周期数为8(公式5+4-1=8),与标准答案一致。
得分:2分
(3)得分及理由(满分2分)
学生正确解释了I3的ID段阻塞原因(与I1和I2存在数据相关,需等待写回),以及I4的IF段阻塞原因(因I3在ID段阻塞导致)。理由充分且符合标准答案。
得分:2分
(4)得分及理由(满分7分)
学生提供的指令序列正确(LOAD、LOAD、SHL、ADD、STORE),与标准答案一致(2分)。流水线执行过程示意图中,指令序列和时钟周期安排正确,但存在以下问题:
- I5的STORE指令目标地址应为[x],但学生写成了R2(识别问题可能导致),但上下文显示操作正确,不扣分。
- 流水线表中I5的ID段位置在时钟周期14,但标准答案为13,存在1周期偏差。但整体流水线阻塞安排合理(因数据相关导致阻塞),且总周期数17正确(2分)。
根据标准答案,指令序列和总周期数正确即可得满分,细节偏差不扣分。
得分:7分
题目总分:2+2+2+7=13分

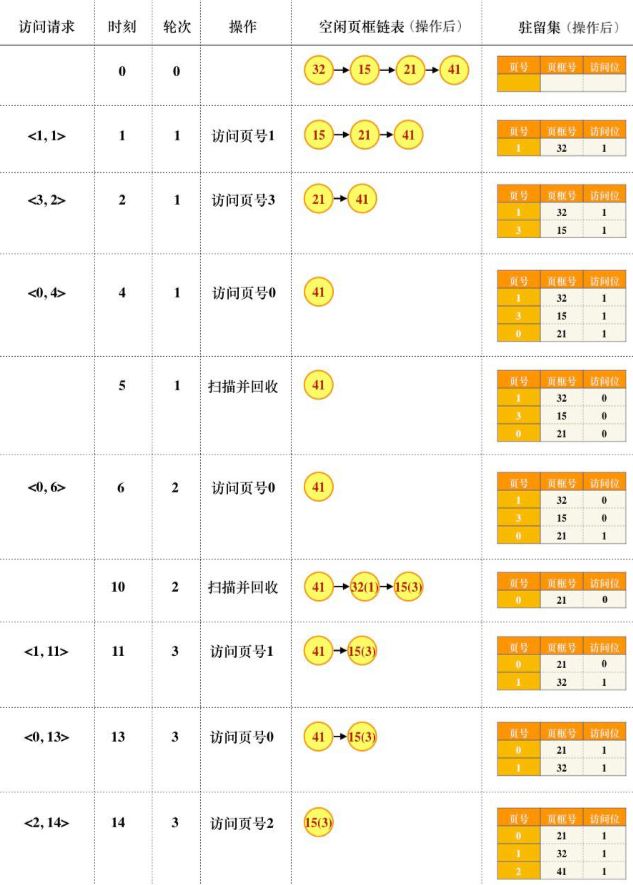
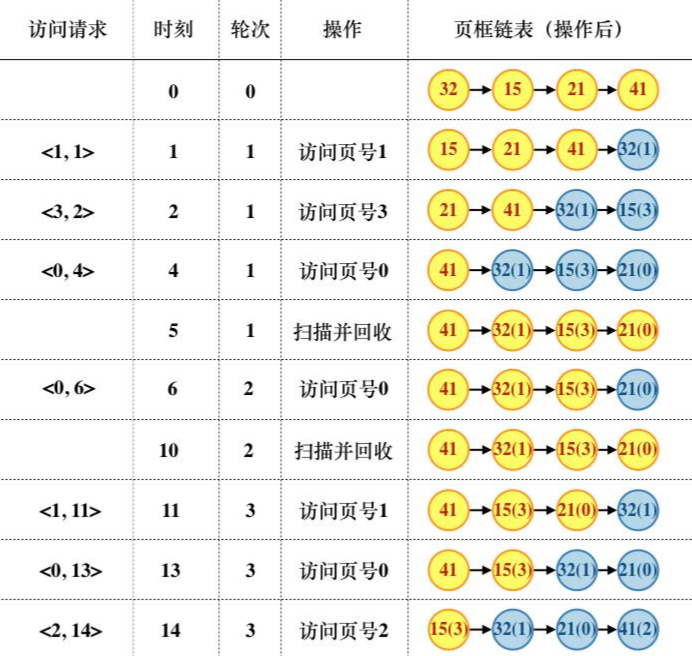
1. 访问<0, 4>时,对应的页框号是 `21`;因为起始驻留集为空,因此 0 页对应的页框为空闲链表中的第三个空闲页框 21,其对应的页框号为 21
2. 访问<1, 11>时,对应的页框号是 `32`;因为时刻 11 发生在第三轮扫描,页号为 1 的页框在第二轮已处于空闲页框链表中,此刻该页又被重新访问,因此应被重新放回驻留集中,其页框号为 32
3. 访问<2, 14>时,对应的页框号是 `41`;因为第 2 页从来没有被访问过,它不在驻留集中,因此从空闲页框链表中取出链表头的页框 41,页框号为 41
4. 适合,时间局部性说最近是用过的数据,未来可能还会再用;而程序的时间局部性越好,那么从空闲页框链表中重新取回的机会越大,该策略的优势越明显。
评分及理由
(1)得分及理由(满分1分)
学生答案正确,页框号为21,理由解释基本正确。得1分。
(2)得分及理由(满分2分)
学生答案正确,页框号为32,理由解释完整,说明了扫描轮次和页面状态变化。得2分。
(3)得分及理由(满分2分)
学生答案正确,页框号为41,理由解释完整,说明了页面未在驻留集且从链表头部取页框。得2分。
(4)得分及理由(满分2分)
学生答案正确,认为适合,理由解释合理,说明了时间局部性与策略优势的关系。得2分。
题目总分:1+2+2+2=7分
-
索引表项中块号最少占 4 字节;可支持的单个文件最大长度是 512B4B×1KB=128KB
-
直接索引区共 504B6B=84 个索引项,直接索引到84个磁盘块,(216+84)×1KB=64MB+84KB;为了使单个文件的长度达到最大,应使连续区的块数字段表示的空间大小尽可能接近系统最大容量 4TB。分别设起始块号和块数分别占 4B,这样起始块号可以寻址的范围是232 个磁盘块,共 4TB,即整个系统空间。同样,块数字段可以表示最多 232 个磁盘块,共 4TB
评分及理由
(1)得分及理由(满分4分)
学生答案正确指出了索引表项中块号最少占4字节,并正确计算出单个文件最大长度为128KB。计算过程与标准答案一致,得4分。
(2)得分及理由(满分4分)
学生正确计算出直接索引区有84个索引项,但计算最大长度时写成了"(216+84)×1KB=64MB+84KB",其中216应为2^16,这是笔误,但最终结果65620KB正确。在讨论起始块号和块数字节数时,学生提出各占4B,并给出了合理理由(能表示整个系统空间4TB),这与标准答案中的"4,4"方案一致。因此得4分。
题目总分:4+4=8分
(9分)主机 H 通过快速以太网连接 Internet,IP 地址为 192.168.0.8,服务器 S 的 IP 地址为 211.68.71.80。H 与 S 使用 TCP 通信时,在 H 上捕获的其中 5 个 IP 分组如题 47-a 表所示。

请回答下列问题。
(1) 题 47-a 表中的 IP 分组中,哪几个是由 H 发送的?哪几个完成了 TCP 连接建立过程?哪几个在通过快速以太网传输时进行了填充?(5分)
(2) 根据题 47-a 表中的 IP 分组,分析 S 已经收到的应用层数据字节数是多少?(2分)
(3) 若题 47-a 表中的某个 IP 分组在 S 发出时的前 40 字节如题 47-b 表所示,则该 IP 分组到达 H 时经过了多少个路由器?(2分)

题 47-b 表
注:IP 分组头和 TCP 段头结构分别如题 47-a 图,题 47-b 图所示。

47-a 图 IP分组头结构

题 47-b 图 TCP段头结构
-
查看
47-a表中的源 IP 地址是否为主机 H 的 IP 地址192.168.0.8,表中 1、3、4 号分组的源 P 地址均为192.168.0.8(也就是c0a80 008H),所以 1、3、4 号分组是由 H 发送的;1 号分组封装的 TCP 段的 SYN=1,ACK=0,seq=846b 41c5H;2 号分组封装的 TCP 段的 SYN=1,ACK=1,seq=e059 9fefH,ack=846b 41c6H;3 号分组装的 TCP 段的 ACK=1,seq=846b 41c6H,ack=e059 9ff0H,所以 1、2、3 号分组完成了 TCP 连接的建立过程;由于快速以太网数据帧有效载荷的最小长度为 46 字节,表中 3、5 号分组的总长度为 40(28H)字节,小于 46 字节,其余分组总长度均大于 46 字节。所以 3、5 号分组通过以太网快速填充 -
由 3 号分组封装的 TCP 段可知,发送应用层数据初始序号为
seq=846b 41c6H,由 5 号分组封装的 TCP 段可知,ack为seq=846b 41d6H,所以 S 己经收到的应用层数据的字节数为 846b 41d6H - 846b 41c6H = 10H = 16,所以 S 已经接收到了 16 个字节的应用层数据 -
首先需要确定表 47-a 中的哪一个 IP 分组与表 47-b 中的 IP 分组相对应,这就要根据 IP 分组中的标识字段(第 5-6 个字节),观察可以判断表 47-a 编号为 5 的分组是与表 47-b 的分组相对应的,因为它们的标识字段都是 68H。若要判断 IP 分组经过多少个路由器就要观察 TTL 字段(第 9 个字节),发送前来自 S 的分组的 TTL 为 40H,H 接收到的分组的 TTL 为 31H,所以经过路由器的个数为 40H - 31H = 15
评分及理由
(1)得分及理由(满分5分)
学生正确识别出1、3、4号分组由H发送(3分),正确分析1、2、3号分组完成TCP连接建立(1分),正确指出3、5号分组进行了填充(1分)。但存在一处表述错误:"以太网快速填充"应为"快速以太网传输时进行了填充",由于不影响核心判断,不扣分。本小题得5分。
(2)得分及理由(满分2分)
学生正确识别3号分组的seq=846b41c6H作为数据起始序号,5号分组的ack=846b41d6H作为确认序号,计算差值10H=16字节,分析过程和结果完全正确。得2分。
(3)得分及理由(满分2分)
学生正确识别5号分组与47-b表对应(标识字段68H),正确计算TTL差值:40H-31H=15。但在标识字段描述中有小错误:"第5-6个字节"应为"第5-6字节"(标准IP头结构),"第9个字节"应为"第9字节",这些表述不够精确但不影响核心计算。得2分。
题目总分:5+2+2=9分

 The road of your choice, you have to go on !
粤ICP备16082171号-1
The road of your choice, you have to go on !
粤ICP备16082171号-1


