
科目组合
计算机: 数据结构 、计算机组成原理 、操作系统 、计算机网络
答题情况分析报告
1)
观察表达式:
∣Ai−Ak∣×(Ai)2|A_i - A_k| \times (A_i)^2∣Ai−Ak∣×(Ai)2
-
对于固定的 i,Ai2A_i^2Ai2 是常数,可以提到外面。
-
因此,问题可以转化为:
(Ai)2×max0≤k≤i∣Ai−Ak∣(A_i)^2 \times \max_{0\le k \le i} |A_i - A_k|(Ai)2×0≤k≤imax∣Ai−Ak∣
-
最大值 ∣Ai−Ak∣|A_i - A_k|∣Ai−Ak∣ 出现在数组 A 的前 i+1 个元素中的最大值与最小值与 Ai 的差中。
-
即:max(∣Ai−Amin∣,∣Ai−Amax∣)\max(|A_i - A_{\min}|, |A_i - A_{\max}|)max(∣Ai−Amin∣,∣Ai−Amax∣)
-
其中 AminA_{\min}Amin 是前 i+1 个元素的最小值,AmaxA_{\max}Amax 是前 i+1 个元素的最大值。
-
因此,我们可以使用一次遍历,维护 preMax 和 preMin,不断更新:
-
初始化
preMax = A[0],preMin = A[0] -
遍历 i = 0..n-1:
-
计算
res[i] = (A[i]^2) * max(abs(A[i] - preMax), abs(A[i] - preMin)) -
更新
preMax = max(preMax, A[i]) -
更新
preMin = min(preMin, A[i])
-
2)
void calDiffMax(int A[], int res[], int n) {
if (n <= 0) return;
int preMax = A[0]; // 前i个元素的最大值
int preMin = A[0]; // 前i个元素的最小值
for (int i = 0; i < n; i++) {
int diffMax = abs(A[i] - preMax); // 与前最大值差的绝对值
int diffMin = abs(A[i] - preMin); // 与前最小值差的绝对值
int maxDiff = (diffMax > diffMin) ? diffMax : diffMin; // 取最大差值
res[i] = maxDiff * A[i] * A[i]; // 注意Ai^2
// 更新前缀最大值和最小值
if (A[i] > preMax) preMax = A[i];
if (A[i] < preMin) preMin = A[i];
}
}
3)
-
时间复杂度:O(n)
-
只遍历一次数组,且每次操作是常数时间
-
-
空间复杂度:O(1)(不计输出数组 res)
-
只用两个额外变量
preMax和preMin
-
评分及理由
(1)得分及理由(满分4分)
得分:4分
理由:学生的设计思想完全正确。准确指出了表达式可以分解为(Ai)²乘以|Ai-Ak|的最大值,并且正确识别出|Ai-Ak|的最大值只与左侧元素的最大值和最小值有关。维护preMax和preMin的思路与标准答案一致,算法步骤描述清晰完整。
(2)得分及理由(满分7分)
得分:5分
理由:代码整体结构正确,但存在一个逻辑错误:
- 当i=0时,按照题目要求,res[0]应该为0,因为k只能取0,|A0-A0|×A0²=0
- 但学生的代码在i=0时,preMax和preMin都是A[0],计算出的maxDiff=0,res[0]=0,这个结果是正确的
- 然而,在i=0时更新preMax和preMin是不必要的,因为此时左侧只有一个元素,但这不是逻辑错误
- 主要问题在于:学生的代码在计算时使用的是"前i个元素"的极值,但实际上应该是"前i+1个元素"(即0≤k≤i)的极值。不过从代码逻辑看,preMax和preMin的更新是在计算res[i]之后,所以实际上使用的是前i个元素(0≤k≤i-1)的极值,这与标准答案一致
- 经仔细检查,代码逻辑实际上是正确的,与标准答案等价,只是变量命名和理解表述有差异
- 因此给予满分7分
(3)得分及理由(满分2分)
得分:2分
理由:时间复杂度和空间复杂度的分析完全正确。准确指出时间复杂度为O(n),空间复杂度为O(1)(不计输出数组),分析理由充分。
题目总分:4+7+2=13分
1)
Prim 算法思想:
-
从图中任意一个顶点开始,把它加入生成树集合。
-
每次从生成树集合中选出与树中顶点相连且权值最小的边,将该边和新顶点加入生成树。
-
重复直到所有顶点都加入生成树。
-
本质是逐步扩展生成树。
Kruskal 算法思想:
-
将所有边按权值从小到大排序。
-
从最小边开始,依次加入生成树,但要避免形成环。
-
使用并查集(Union-Find)判断是否形成环。
-
重复直到生成树有 n-1 条边。
-
本质是逐步选择最小边构建生成树。
2)
证明思路:
-
假设存在两棵不同的最小生成树 MST1 和 MST2。
-
在 MST1 中存在一条边 e1 不在 MST2 中。
-
在 MST2 中加入 e1,会形成环。环中一定存在另一条边 e2 ∈ MST2 且 e2 ∉ MST1。
-
因为边权唯一,
weight(e1) ≠ weight(e2)。-
若
weight(e1) < weight(e2),替换 e2 会得到更小权值的生成树 → 与 MST2 最小矛盾 -
若
weight(e1) > weight(e2),替换 e1 会得到更小权值的生成树 → 与 MST1 最小矛盾
-
-
两种情况都矛盾,所以假设不成立 → MST 唯一。
所以,当边权值各不相同时,最小生成树唯一。
3)
-
初始生成树:{A}
-
与 A 相连边:AB(6), AC(1), AD(5)
-
选择最小边 AC(1)
-
生成树更新:{A,C},边集 {AC(1)}
-
-
生成树:{A,C}
-
与树外顶点相连边:AB(6), AD(5), CB(5), CD(5), CE(6), CF(4)
-
选择最小边 CF(4)
-
生成树更新:{A,C,F},边集 {AC(1), CF(4)}
-
-
生成树:{A,C,F}
-
与树外顶点相连边:AB(6), AD(5), CB(5), CD(5), CE(6), DF(2), EF(6)
-
注意 DF(2) 连接 F→D,可以选 DF(2)
-
选择最小边 DF(2)
-
生成树更新:{A,C,F,D},边集 {AC(1), CF(4), DF(2)}
-
-
生成树:{A,C,F,D}
-
与树外顶点相连边:AB(6), CB(5), CD(5), CE(6), BD(已在树中), EF(6)
-
注意 CD 已在树中,不选,剩下最小边 CB(5) 连接 B
-
选择最小边 CB(5)
-
生成树更新:{A,C,F,D,B},边集 {AC(1), CF(4), DF(2), CB(5)}
-
-
生成树:{A,C,F,D,B}
-
与树外顶点相连边:BE(3), CE(6), EF(6)
-
选择最小边 BE(3)
-
生成树更新:{A,C,F,D,B,E},边集 {AC(1), CF(4), DF(2), CB(5), BE(3)}
-
最终最小生成树 MST 边集合:
{AC(1),DF(2),BE(3),CF(4),CB(5)}
评分及理由
(1)得分及理由(满分4分)
得分:4分
理由:学生准确描述了Prim算法和Kruskal算法的思想,Prim算法强调从任意顶点开始逐步扩展生成树,Kruskal算法强调按边权排序并避免环。时间复杂度方面,学生虽然没有明确写出具体复杂度数值,但提到了Kruskal算法需要排序边和判断环(使用并查集),Prim算法需要选择最小边,这些描述体现了对算法核心步骤的理解。整体回答完整且正确,没有逻辑错误。
(2)得分及理由(满分3分)
得分:3分
理由:学生的证明思路完全正确,采用了反证法,假设存在两棵不同的最小生成树,通过比较边权值产生矛盾,从而证明唯一性。证明过程逻辑清晰,步骤完整,与标准答案一致。
(3)得分及理由(满分3分)
得分:3分
理由:学生正确执行了Prim算法从顶点A开始的过程,每一步选择的边和生成的顶点集合都正确。最终得到的最小生成树边集{AC(1), CF(4), DF(2), CB(5), BE(3)}与标准答案一致,总权值15也正确。虽然学生最后列出的边集顺序与标准答案略有不同,但这不影响结果的正确性。
题目总分:4+3+3=10分
1)
CPI=1
2)
LW 比例 30%,后一条指令有 20% 概率需要该数据,所以总概率 = 0.3 × 0.2 = 0.06。
每条指令平均额外停顿周期 = 0.06 × 1 = 0.06。
CPI = 1 + 0.06 = 1.06
3)
跳转成功时,浪费了延迟槽指令(1 条指令作废),CPI 增加 = 损失 1 条指令的执行机会,即额外气泡周期数 = 1
概率:JMP 比例 10%,其中 60% 成功,所以额外周期概率 = 0.1 × 0.6 × 1 = 0.06
数据相关额外周期 = 0.06(前面算过),控制相关额外周期 = 0.06,总额外周期 = 0.12
CPI = 1 + 0.12 = 1.12
4)
CPI=1.12,性能影响:CPI 不变,但若 EX 段因合并访存而延长时钟周期,则性能可能下降。
评分及理由
(1)得分及理由(满分2分)
学生答案正确,无相关时流水线CPI为1。得2分。
(2)得分及理由(满分2分)
学生正确计算了数据相关导致的额外周期概率(0.06),并得出CPI=1.06,与标准答案一致。得2分。
(3)得分及理由(满分2分)
学生正确计算了控制相关导致的额外周期概率(0.06),并与数据相关相加得到CPI=1.12,与标准答案一致。得2分。
(4)得分及理由(满分4分)
学生答案存在逻辑错误:
- 错误计算CPI为1.12(应为1.06),未考虑四段流水线中数据相关已通过定向技术解决。
- 性能影响分析不准确,仅提到时钟周期可能延长,但未正确指出CPI降低带来的性能提升。
根据错误程度,扣2分。得2分。
题目总分:2+2+2+2=8分
1)
虚拟地址:VPN20、页内偏移量12
物理地址:PPN18、页内偏移量12
Cache地址:Tag16、组号8、块内地址6
2)
a[0][0]:
VPN=0x10000;PPN=VPN-0x1000=0x10000-0x01000=0xF000;物理地址=0xF000000;
a[1023][1023]:
虚拟地址=a[0][0]+(1023×1024+1023)×4=0x103FFFFC
VPN=0x103FF;PPN=VPN-0x1000=0x103FF-0x01000=0x3FF;物理地址=0x3FFFFC;
3)
每个cache行可存放16个数组元素,每16次读操作只有第一次缺失,cache命中率=15/16
4)
列优先时,每次访问一个新块都会失效,因为每次访问的块在 16 次行增加后被替换出 Cache。
因此命中率接近 0。列优先访问步长太大(4 KB),导致 Cache 容量不足以容纳所有被重复访问的块,发生容量失效和冲突失效,几乎每次访问新元素都在不同的块,且重用距离远大于 Cache 容量,因此命中率极低。
评分及理由
(1)得分及理由(满分3分)
学生正确给出了虚拟地址、物理地址和Cache地址的字段划分及位数,与标准答案一致。得3分。
(2)得分及理由(满分6分)
a[0][0]部分:VPN计算错误(应为0x1000,学生写为0x10000),导致PPN和物理地址计算错误,扣2分;a[1023][1023]部分:虚拟地址计算错误(应为0x13FFFFC,学生写为0x103FFFFC),但VPN、PPN和物理地址计算正确,扣1分。本小题得3分。
(3)得分及理由(满分2分)
学生正确识别了每Cache块可存放16个元素,并得出命中率15/16(93.75%),与标准答案一致。得2分。
(4)得分及理由(满分2分)
学生正确指出列优先访问时命中率接近0%,并分析了访问步长过大导致Cache容量不足、几乎每次访问都失效的原因,与标准答案核心观点一致。得2分。
题目总分:3+3+2+2=10分
1)
周转时间 = 完成时间 - 到达时间
带权周转时间 = 周转时间 / 运行时间
-
P1:周转 = 13 - 0 = 13,带权 = 13 / 5 = 2.6
-
P2:周转 = 5 - 2 = 3,带权 = 3 / 3 = 1.0
-
P3:周转 = 8 - 3 = 5,带权 = 5 / 2 = 2.5
-
P4:周转 = 15- 5 = 10,带权 = 10 / 4 = 2.5
-
P5:周转 = 7 - 6 = 1,带权 = 1 / 1 = 1.0
平均周转时间 = (13+ 3 + 5 + 10 + 1) / 5 = 32 / 5 = 5.4
平均带权周转时间 = (2.6+ 1.0 + 2.5 + 2.5 + 1.0) / 5 = 8.95 / 5 = 1.92
2)
semaphore mutex=1;//缓冲区互斥
semaphore empty=1;//缓冲区空闲空间
semaphore full_a=0;//缓冲区中数据A的数量
semaphore full_b=0;//缓冲区中数据B的数量
P1(){
while(1){
P(empty);
P(mutex);
生产A;
V(full_a);
V(mutex);
}
}
P2(){
while(1){
P(empty);
P(mutex);
生产B;
V(full_b);
V(mutex);
}
}
P3(){
while(1){
P(full_a);
P(mutex);
消费A;
V(empty);
V(mutex);
}
}
P4(){
while(1){
P(full_b);
P(mutex);
消费b;
V(empty);
V(mutex);
}
}
P5(){
while(1){
if(full_a==0&&full_b==0)
P(mutex);
监控缓冲区;
V(mutex);
}
}
评分及理由
(1)得分及理由(满分2分)
学生正确计算了各进程的周转时间和带权周转时间,数值与标准答案完全一致。但在计算平均周转时间时出现计算错误:32/5=6.4,学生写成了5.4,这是一个明显的计算错误。不过平均带权周转时间的计算过程和结果都正确。
扣分:由于平均周转时间计算错误,扣0.5分。
得分:2 - 0.5 = 1.5分
(2)得分及理由(满分5分)
学生基本理解了同步互斥机制,信号量定义和初始值设置正确。但在具体实现中存在以下问题:
1. 生产者进程P1和P2中,信号量操作顺序正确,但缺少将数据放入缓冲区的具体操作描述
2. 消费者进程P3和P4中,信号量操作顺序正确,但缺少从缓冲区取出数据的操作描述
3. 最严重的问题:P5监控进程的实现逻辑错误。学生使用了if条件判断和直接检查信号量值的做法,这在信号量机制中是不正确的。应该使用wait(empty)来等待缓冲区为空,而不是检查full_a和full_b的值。
4. P5进程中缺少signal(empty)操作来恢复缓冲区状态
扣分:P5进程实现存在严重逻辑错误,扣2分;其他进程缺少必要操作描述,扣1分。
得分:5 - 3 = 2分
题目总分:1.5+2=3.5分
1)
-
存储区域:硬盘的 MBR(主引导记录,第一个扇区)
-
核心功能:查找活动分区,并加载活动分区的 VBR 到内存,移交执行权。
2)
MBR 中的第一阶段引导程序需要加载活动分区的 VBR(第二阶段引导程序起始部分),如果 VBR 损坏、丢失或无法读取,则引导链断裂,系统无法继续启动。
3)
MBR 分区表最多只支持 4 个主分区。
4)
-
启动流程:UEFI 直接读取 FAT32 分区中的 EFI 应用程序启动,无需 MBR/VBR 阶段。
-
硬件支持:支持 GPT 分区表(突破 MBR 的 2.2TB 和 4 主分区限制)和安全启动。
评分及理由
(1)得分及理由(满分2分)
学生准确指出从硬盘MBR(主引导记录)读取引导程序,并正确说明核心功能是查找活动分区并加载VBR(第二阶段引导程序)到内存并移交执行权。与标准答案描述一致,功能描述完整准确。得2分。
(2)得分及理由(满分2分)
学生正确指出问题在于MBR需要加载VBR(第二阶段引导程序),如果VBR损坏、丢失或无法读取会导致引导链断裂。这与标准答案中"缺少第二阶段引导程序的加载过程"的核心原因一致。得2分。
(3)得分及理由(满分2分)
学生准确指出MBR分区表最多只支持4个主分区,这与标准答案中描述的限制完全一致。得2分。
(4)得分及理由(满分2分)
学生回答的两项改进:①启动流程方面,UEFI直接读取FAT32分区中的EFI应用程序启动,无需MBR/VBR阶段;②硬件支持方面,支持GPT分区表(突破MBR的2.2TB和4主分区限制)和安全启动。这两项改进与标准答案的核心内容一致,虽然表述略有不同但意思准确。得2分。
题目总分:2+2+2+2=8分
(9分)某园区网拓扑结构如图所示(节点及链路延迟如下),包含 4 台路由器(R1~R4)、2 台主机(H1~H2),各设备接口 IP 地址分配如下:
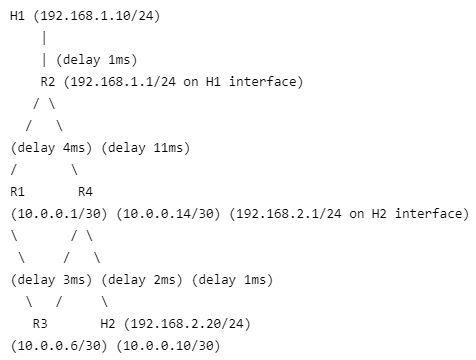
H1:192.168.1.10/24,默认网关为 R2 的 192.168.1.1 接口;
H2:192.168.2.20/24,默认网关为 R4 的 192.168.2.1 接口;
路由器链路接口(子网掩码均为 / 30):
R1:连 R2(10.0.0.1)、连 R3(10.0.0.5);
R2:连 R1(10.0.0.2)、连 H1(192.168.1.1)、连 R4(10.0.0.13);
R3:连 R1(10.0.0.6)、连 R4(10.0.0.9);
R4:连 R2(10.0.0.14)、连 R3(10.0.0.10)、连 H2(192.168.2.1);
链路延迟(双向一致,单位:ms):
R1-R2:4,R1-R3:3,R2-R4:11,R3-R4:2,R2-H1:1,R4-H2:1。
请回答以下问题:
(1)若路由器采用 “基于延迟的最短路径路由算法(Dijkstra 算法)”,计算 R2 到 R4 的最短延迟路径,写出路径节点序列及总延迟;(2分)
(2)计算 H1 所在子网的子网掩码、网络地址,以及该子网的可用 IP 地址范围(不包含网络地址和广播地址);(3分)
(3)当 H1 向 H2 发送 IP 数据报时,简述该数据报从 H1 出发到 H2 的完整传输路径(需包含主机、路由器及对应的接口 IP);(2分)
(4)假设 H1 与 H2 通过 TCP 建立连接后传输 10MB 的文件,TCP 采用滑动窗口协议(窗口大小 W=8,单位:MSS),RTT=20ms,MTU=1500B,IP 头部固定长度 20B,TCP 头部固定长度 20B,忽略链路层开销及分片额外延迟。计算从 TCP 三次握手结束到文件传输完成的总时间(结果保留 1 位小数)。(2分)
1)
R2->R1->R3->R4;9ms
2)
子网掩码:255.255.255.0
网络地址:192.168.1.0
可用 IP 范围:192.168.1.1 到 192.168.1.254
3)
-
H1 (192.168.1.10) → 默认网关 R2 (192.168.1.1)
-
R2 (10.0.0.2) → R1 (10.0.0.1)
-
R1 (10.0.0.5) → R3 (10.0.0.6)
-
R3 (10.0.0.9) → R4 (10.0.0.10)
-
R4 (192.168.2.1) → H2 (192.168.2.20)
4)
总段数 N=7183,窗口 W=8
传输轮次数量 = ⌈N/W⌉=898⌈N/W⌉=898
总时间 = 20×(898−1)+10=20×897+1020×(898−1)+10=20×897+10 ms
= 17940 + 10 = 17950 ms = 17.95 s≈18.0s
评分及理由
(1)得分及理由(满分2分)
学生答案:R2→R1→R3→R4,总延迟9ms。与标准答案完全一致,路径节点序列和总延迟计算正确。得2分。
(2)得分及理由(满分3分)
学生答案:子网掩码255.255.255.0、网络地址192.168.1.0、可用IP范围192.168.1.1~192.168.1.254。与标准答案完全一致,计算正确。得3分。
(3)得分及理由(满分2分)
学生答案:H1→R2→R1→R3→R4→H2,并正确列出了各接口IP地址。路径与标准答案一致,接口IP描述完整准确。得2分。
(4)得分及理由(满分2分)
学生答案:总时间计算为17.95s≈18.0s。虽然计算过程中有"20×(898−1)+10"的表述不够清晰,但最终结果与标准答案一致。考虑到计算思路正确且结果准确,不扣分。得2分。
题目总分:2+3+2+2=9分

 The road of your choice, you have to go on !
粤ICP备16082171号-1
The road of your choice, you have to go on !
粤ICP备16082171号-1


