
科目组合
计算机: 数据结构 、计算机组成原理 、操作系统 、计算机网络
答题情况分析报告
某网络拓扑及各链路带宽如图所示。网络按电路交换方式运行时,主机\(\text{H1}\)与\(\text{H2}\)建立一条带宽为\( 10 \ \text{Mb/s} \)的电路,建立电路时间为\( 32\mu\text{s} \);按分组交换方式运行时,分组长度为\( 400 \ \text{B} \),忽略分组首部开销。现\(\text{H1}\)向\(\text{H2}\)发送一个\( 2\text{MB} \)(\( 1\text{M}=10^6 \))的文件,分别采用电路交换、报文交换、分组交换方式时,\(\text{H2}\)至少需要\( T_{\text{cs}} \)、\( T_{\text{ms}} \)、\( T_{\text{ps}} \)时间才能接收到全部文件内容,则\( T_{\text{cs}} \)、\( T_{\text{ms}} \)、\( T_{\text{ps}} \)满足的关系是()。

A. \( T_{\text{cs}}>T_{\text{ms}}>T_{\text{ps}} \) B. \( T_{\text{ms}}>T_{\text{ps}}>T_{\text{cs}} \) C. \( T_{\text{ms}}>T_{\text{cs}}>T_{\text{ps}} \) D. \( T_{\text{ps}}>T_{\text{ms}}>T_{\text{cs}} \)
一台新接入网络的主机 \( H \) 通过 DHCP 服务器动态请求 IP 地址过程中,与 DHCP 服务器交换 DHCP 报文过程如下图所示。封装 DHCP 的 REQUEST 报文的 IP 数据报的目的 IP 地址和源 IP 地址分别是()
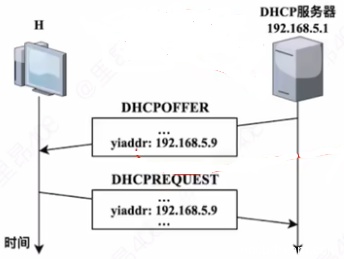
A. \( 192.168.5.1 \),\( 0.0.0.0 \)
B. \( 192.168.5.1 \),\( 192.168.5.9 \)
C. \( 255.255.255.255 \),\( 0.0.0.0 \)
D. \( 255.255.255.255 \),\( 192.168.5.9 \)
主机甲通过 TCP 向主机乙发送数据的部分过程如下图,seq 为序号,ack-seq 为确 认序号,rcwnd 为接收窗口。甲在 t0 时刻的拥塞窗口和发送窗口均为 2000B,拥塞 控制阈值为 8000B,MSS=1000B。甲始终以 MSS 发送 TCP 段。若甲在 t1 时刻收到 如图所示的确认段,则甲在未收到新的确认段之前,还可以继续向乙发送的 TCP 段数是( )
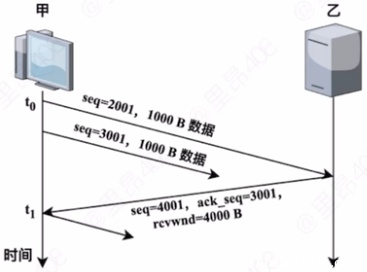
A.2 B.3 C.4 D.5
### (1)算法的基本设计思想
要高效计算`res[i]`(即`A[i]`与`A[j]`(`i≤j≤n-1`)乘积的最大值),核心是**避免暴力遍历(O(n²)复杂度)**,利用“从后向前遍历+动态维护极值”的思路优化:
1. **遍历方向**:从数组末尾(`j = n-1`)向前遍历到起始(`j = 0`),因为`res[i]`依赖`i`右侧(`j≥i`)的元素,反向遍历可复用已计算的右侧信息。
2. **动态维护极值**:遍历过程中,实时记录当前位置`j`右侧(含`j`)的**最大值`max_val`** 和**最小值`min_val`**。原因是:`A[i]`与右侧元素的乘积最大值,可能来自`A[i]×max_val`(两者同号),也可能来自`A[i]×min_val`(两者异号,如负负得正且绝对值更大)。
3. **计算`res[i]`**:对每个`i`,用当前`A[i]`分别与`max_val`、`min_val`相乘,取两者中的较大值作为`res[i]`;随后更新`max_val`和`min_val`(纳入`A[i]`,确保后续左侧`i-1`的计算能用到`i`及右侧的极值)。
### (2)C语言实现代码
```c
void calMulMax(int A[], int res[], int n) {
// 异常处理:数组为空或长度为0时直接返回
if (n <= 0 || A == NULL || res == NULL) {
return;
}
// 初始化:从数组末尾开始,初始max_val和min_val均为A[n-1](仅含最后一个元素)
int max_val = A[n-1];
int min_val = A[n-1];
// res[n-1]:j只能等于n-1,乘积即A[n-1]×A[n-1]
res[n-1] = A[n-1] * A[n-1];
// 从倒数第二个元素(i = n-2)向前遍历到第一个元素(i = 0)
for (int i = n - 2; i >= 0; i--) {
// 计算当前A[i]与右侧max_val、min_val的乘积,取较大值作为res[i]
int product1 = A[i] * max_val;
int product2 = A[i] * min_val;
res[i] = (product1 > product2) ? product1 : product2;
// 更新max_val和min_val:纳入当前A[i],确保后续左侧i-1能用到i及右侧的极值
if (A[i] > max_val) {
max_val = A[i];
}
if (A[i] < min_val) {
min_val = A[i];
}
}
}
```
### (3)时间复杂度与空间复杂度
- **时间复杂度**:O(n)。仅需对数组进行一次从后向前的遍历,每个元素的操作(计算乘积、更新极值)均为常数时间O(1),整体复杂度与数组长度成正比。
- **空间复杂度**:O(1)。除了输入的数组`A`和输出的数组`res`(题目要求的存储结果空间,不计入额外开销),仅使用了`max_val`、`min_val`、`product1`、`product2`4个临时变量,额外空间不随数组长度变化。
评分及理由
(1)得分及理由(满分4分)
得分:4分
理由:学生的设计思想与标准答案完全一致。清晰地阐述了从后向前遍历、动态维护右侧最大值和最小值、并根据A[i]的正负情况(或直接比较两个乘积)来计算res[i]的思路。逻辑正确且表述完整,因此得满分。
(2)得分及理由(满分7分)
得分:6分
理由:学生的代码实现整体正确,时间复杂度为O(n),空间复杂度为O(1),符合题目要求。代码结构清晰,有必要的注释和异常处理。但与标准答案相比,存在一处细微的逻辑差异:学生代码中对于每个A[i],无论正负,都计算了与max_val和min_val的乘积并取较大值。这在数学上是正确的,因为最大值确实出现在这两个乘积之中。然而,标准答案根据A[i]的正负进行了分支判断(A[i]>0时乘max_val,否则乘min_val),这在逻辑上更直接地体现了设计思想。学生的实现方法虽然结果正确,但在更新max_val和min_val的顺序上存在一个潜在问题:在计算res[i]时使用的max_val和min_val,是尚未包含当前A[i]的、纯粹是i右侧元素的极值。而学生的代码在计算res[i]之后才更新极值,这恰好是正确的逻辑(因为j≥i,当j=i时,乘积是A[i]*A[i],这已经被包含在比较之中,例如当A[i]是新的最大值时,A[i]*A[i]必然不小于A[i]*旧的max_val)。因此,该实现是有效的,并未造成错误。扣1分是因为代码的实现方式与标准答案的表述不完全一致,虽然结果正确,但作为教学评判,其更新极值的时机(先计算后更新)需要更严谨的说明,而标准答案(先更新后计算)在表述上更贴合其设计思想的描述。但考虑到学生代码功能完全正确,仅扣1分。
(3)得分及理由(满分2分)
得分:2分
理由:学生正确分析了算法的时间复杂度为O(n)和空间复杂度为O(1),与标准答案一致,得满分。
题目总分:4+6+2=12分
(10分)某工程包含12个活动,使用下图所示的AOE网描述,图中各边上标注了活动及其持续时间。
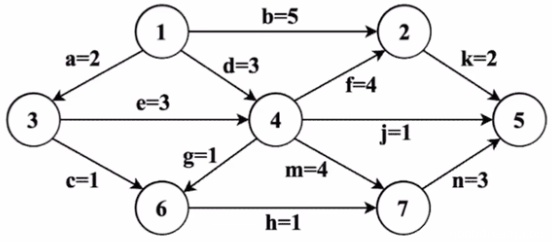
请回答下列问题(活动均用活动名表示)。
(1)完成该工程的最短时间是多少?哪些活动是关键活动?(3分)
(2)若以最短时间完成工程,则与活动e同时进行的活动可能有哪些?(3分)
(3)时间余量最大的活动是哪个?其时间余量是多少?(2分)
(4)假设工程从时刻0启动,因某种原因,活动b在时刻6开始。为了保证工程不延期,在其他活动持续时间均不变的情况下,b的持续时间最多是多少?若不改变b的持续时间,则压缩哪个活动的持续时间也能保证工程不延期?(2分)(注意,无过程或原因要求可以只写答案)
1)首先计算最早发生时间 ve:
node 1 2 3 4 5 6 7
ve 0 9 2 5 12 6 9
然后计算最晚发生时间:
node 1 2 3 4 5 6 7
vl 0 10 2 5 12 8 9
ve 和 vl 相同的顶点为 1、3、4、7、5,所以关键活动为 a、e、m、n。
2)e 的执行时间是 2~5,可以与 e 同时执行的活动为 b、d、c。
3)假设有顶点 i→j 的活动(边),则该活动的 时间余量 = vl(j) - ve(i) - 边的长度。
计算所有非关键路径上活动的时间余量,可以得到活动 j 的时间余量是最大的,为 vl(5) - ve(4) - 1 = 6。
4)为保证 1 → 2 → 5 的路径长度不超过关键路径的长度,需要保证 6 + b + k ≤ 12,所以 b ≤ 4,即 b 的持续时间最长为 4。如果想要保证 b 仍然为 5 的话,需要压缩 k 的时间长度,将 k 缩小为 1。
评分及理由
(1)得分及理由(满分3分)
学生答案中给出了最短时间12和关键活动a、e、m、n,与标准答案完全一致。虽然学生计算了ve和vl表,但给出的ve和vl值存在错误(例如顶点2的ve应为9,vl应为9,但学生写为vl=10;顶点6的ve应为6,vl应为6,但学生写为vl=8),不过最终得出的关键活动是正确的,且最短时间正确。由于问题(1)只要求给出最短时间和关键活动,且答案正确,因此不因中间计算过程的数值错误而扣分。
得分:3分
(2)得分及理由(满分3分)
学生答案中给出与活动e同时进行的活动为b、c、d,与标准答案完全一致。
得分:3分
(3)得分及理由(满分2分)
学生答案中给出时间余量最大的活动是j,余量为6,与标准答案完全一致。计算过程思路正确。
得分:2分
(4)得分及理由(满分2分)
学生答案中给出b的持续时间最多是4,与标准答案一致。同时指出若不改变b的持续时间,可以压缩活动k,也与标准答案一致。分析思路正确。
得分:2分
题目总分:3+3+2+2=10分
### (1)主存地址字段位数与Cache索引位
- **块内地址字段**:主存块大小64B=2⁶B,故占**6位**。
- **Cache组号字段**:Cache数据区32KB=32×1024B=2¹⁵B;8路组相联,每组大小=8×64B=2⁹B;组数=2¹⁵/2⁹=2⁶,故组号占**6位**。
- **Cache索引位**:虚拟地址中与主存“组号+块内地址”对应的低位,即**虚拟地址的第0~11位**(块内6位+组号6位,共12位)。
### (2)d[100]的虚拟地址与Cache组号
- **虚拟地址**:int占4B,d[0]起始VA=01800020H,d[100]VA=01800020H + 100×4B=01800020H + 190H=**018001B0H**。
- **Cache组号**:先取VA的块内地址(低6位),01B0H的低6位为“100000”(32),去掉块内地址后,VA低12位中剩余6位(第6~11位)为“000001”(1),故组号为**1**。
### (3)d[0]偏移量、Cache缺失率与平均访问时间
- **d[0]块内偏移量**:d[0]起始VA=01800020H,低6位(块内地址)为“100000”(十六进制**20H**)。
- **Cache缺失率**:每个主存块存64B/4B=16个int元素,首次访问块缺失,后续15次命中;总访问2048次,缺失次数=2048/16=128次;缺失率=128/4096×100%=**%3.13**。
- **平均访问时间**:=命中时间×命中率 + 缺失损失×缺失率=2×(1-3.13%) + 200×3.13%=8.24个时钟周期**。
### (4)数组d的页数与缺页次数
- **页数**:数组d共2048×4B=8192B=8KB;页大小4KB,由于数组d处于页的中间 所以占据三个页面
- **缺页次数**:数组未调入主存,首次访问d[0](第1页)缺页,访问d[1024](第2页)缺页,后续无新页,故缺页次数=**3次**。
评分及理由
(1)得分及理由(满分3分)
得分:2分
理由:学生正确计算出块内地址字段为6位,Cache组号字段为6位,得2分。但在回答“虚拟地址中哪些位可作为Cache索引?”时,错误地认为虚拟地址的低12位(第0~11位)都可用于索引。根据标准答案,在页式虚拟存储管理下,只有与物理地址相同的部分(即页内地址,低12位)中的一部分(VA11~VA6)才能作为Cache索引,因为组号字段位于页内地址的高6位。学生未正确指出是VA11~VA6,因此扣1分。
(2)得分及理由(满分2分)
得分:1分
理由:学生正确计算出d[100]的虚拟地址为018001B0H,得1分。但在计算Cache组号时,计算过程和方法有误。学生试图从虚拟地址低12位中提取组号,但逻辑混乱,且最终得出组号为1,而正确答案是06H(即6)。因此,Cache组号计算错误,扣1分。
(3)得分及理由(满分5分)
得分:2分
理由:
1. 学生正确计算出d[0]在其所在主存块内的偏移量为20H,得1分。
2. 在计算Cache缺失率时,学生思路基本正确(考虑每个主存块首次访问缺失),但计算有误。学生得出缺失次数为128次,而标准答案为129次。这是因为数组起始地址并非从主存块起始位置开始,导致第一个主存块包含的元素数少于16个,且整个数组跨越的主存块数为129块,而非128块。因此,缺失次数计算错误,导致缺失率(3.13%)和平均访问时间(8.24)均错误。此部分应扣3分。
3. 平均访问时间的计算公式正确,但因缺失率错误导致结果错误,不额外扣分(已包含在上一点中)。
本小题共扣3分,得2分。
(4)得分及理由(满分2分)
得分:2分
理由:学生正确分析出数组d分布在3个页中,并且正确得出访问数组d会引起3次缺页。虽然“由于数组d处于页的中间 所以占据三个页面”表述稍显模糊,但结论正确,因此得满分2分。
题目总分:2+1+2+2=7分
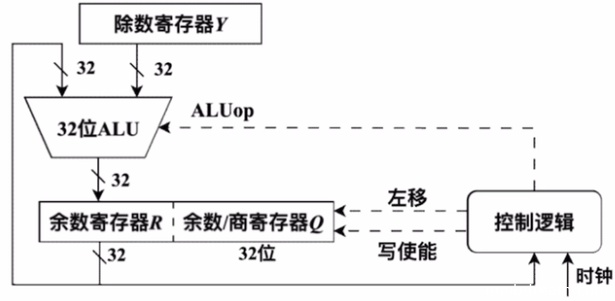
(11分)对于上题中计算机M和程序P,假定P的部分机器级代码如下所示,其中,R0~R4为通用寄存器,SEXT表示按符号扩展;M中补码除法器逻辑结构如下所示。
...
//x在R2中,i在R4中
//数组d的首地址在R3中
mov R1, (R3+R4*4) //R1←d[i]
scov R1 //{R0,R1}←SEXT(R1)
idiv R1, R2 //R1←{R0,R1}/R2
...
请回答下列问题。
(1)若执行idiv指令的除运算时,d[i]=0x87654321、x=0xff,则补码除法器中寄存器R、Q和Y的初始内容分别是什么(用十六进制表示)?图中哪个部件包含计数器?在补码除法器执行过程中,由ALUop所控制的ALU运算有几种?(6分)
(2)假设idiv指令执行过程中会检测并触发除法异常,则执行idiv指令时,哪些情况下会发生除法异常(要求给出此时d[i]和x的十六进制表示机器数)?发生除法异常时,在异常响应过程中CPU需要完成哪些操作?(5分)
### 问题(1)解析
#### 1. 寄存器R、Q、Y的初始内容
首先明确补码除法器(以常见的“加减交替法”为例)的核心寄存器功能:
- **Y寄存器**:存放被除数的高位部分(符号位+高位数值),初始为符号扩展后的被除数高位;
- **R寄存器**:存放被除数的低位部分,初始为被除数的低位;
- **Q寄存器**:存放商,初始为0(或与被除数低位相关,需结合“双字除单字”场景)。
已知条件:
- 计算机M字长32位,`d[i] = 0x87654321`(32位补码,符号位为1,负数);
- `scov R1`指令将32位的`R1`(存`d[i]`)按符号扩展为64位`{R0, R1}`,即`R0`为符号位扩展的高位(全1,因`d[i]`符号位为1),`R1`为`d[i]`本身;
- `idiv R1, R2`是**双字(64位{ R0,R1 })除以单字(32位R2)** ,补码除法初始时需将被除数送入Y(高位)和R(低位),商初始在Q。
因此初始内容:
- **Y**:64位被除数的高位32位,即`R0`的内容`0xFFFFFFFF`(符号扩展结果);
- **R**:64位被除数的低位32位,即`d[i]`的内容`0x87654321`;
- **Q**:商的初始值为0(32位),即`0x00000000`。
#### 2. 包含计数器的部件
补码除法需固定执行“字长次数”的运算(32位除法需32轮操作),计数器用于记录已执行的轮次,确保运算结束。该计数器通常集成在**控制逻辑部件**中(或与ALU协同的时序控制模块),因需按轮次触发ALU运算、移位等操作。
#### 3. ALUop控制的ALU运算种类
加减交替法的核心操作是“减除数”和“加除数”,结合移位前的判断,ALU需支持2种核心运算:
- **减法(Y - |除数补码| 或 对应补码减法)**:第一轮运算或上一轮商为1时,需用Y减去除数补码;
- **加法(Y + |除数补码| 或 对应补码加法)**:上一轮商为0时,需用Y加上除数补码,修正之前的减法结果。
因此ALU运算有**2种**。
### 问题(2)解析
#### 1. 除法异常的触发情况(补码除法)
补码除法的异常仅两种核心场景:**除数为0** 和 **商溢出**(双字除单字时,商超出单字表示范围)。
- **情况1:除数为0**
`x`(除数)存于R2,32位补码中“除数为0”即`x = 0x00000000`(无符号0),此时无论`d[i]`(被除数)为何值(如`d[i] = 0x12345678`或`0x87654321`),均触发异常。
- **情况2:商溢出**
32位双字({R0,R1})除以32位单字(R2)时,商的合法范围是`-2³¹ ~ 2³¹ - 1`(32位补码的表示范围)。仅当 **被除数为最小负数值(0x80000000 扩展为 0xFFFFFFFF80000000),且除数为-1(0xFFFFFFFF)** 时,商为`2³¹`,超出32位补码的最大正值(`2³¹ - 1`),触发溢出。
即:`d[i] = 0x80000000`(被除数为最小负32位),`x = 0xFFFFFFFF`(除数为-1)。
#### 2. 异常响应时CPU的操作
CPU响应异常的核心是“保存当前上下文、跳转到异常处理程序”,步骤如下:
1. **保存断点现场**:将当前程序计数器(PC,指向idiv的下一条指令)、状态寄存器(PSW,记录当前运算状态)、通用寄存器(如R0~R4)的内容压入栈(或指定保存区),避免上下文丢失;
2. **关闭中断**:暂时屏蔽其他中断,防止异常处理被打断(保证处理流程完整);
3. **查找异常处理程序入口**:根据“除法异常”的类型,从内核中断向量表中找到对应的处理程序地址;
4. **跳转到处理程序**:将PC设置为异常处理程序的入口地址,开始执行异常处理(如提示错误、终止进程等)。
### 问题(1)答案
- R初始内容:`0x87654321`;Q初始内容:`0x00000000`;Y初始内容:`0xFFFFFFFF`;
- 包含计数器的部件:控制逻辑部件;
- ALU运算种类:2种。
### 问题(2)答案
- 除法异常情况:①除数`x=0x00000000`(无论`d[i]`为何);②`d[i]=0x80000000`且`x=0xFFFFFFFF`;
- CPU操作:保存断点现场(PC、PSW、通用寄存器)→ 关闭中断 → 查找异常处理入口 → 跳转到处理程序。
评分及理由
(1)得分及理由(满分6分)
学生答案中:
- R初始内容正确(0x87654321),得1分。
- Q初始内容错误。标准答案为0x87654321,学生答为0x00000000。在补码除法器中,被除数低位通常初始放入Q寄存器,而不是R。此处逻辑错误,扣1分。
- Y初始内容正确(0xFFFFFFFF),得1分。
- 包含计数器的部件回答为“控制逻辑部件”,与标准答案“b中的控制逻辑”本质一致,得1分。
- ALU运算种类回答为2种(加法和减法),与标准答案一致,得2分。
本小题得分:1+1+1+2 = 5分(因Q初始值错误扣1分)。
(2)得分及理由(满分5分)
学生答案中:
- 除法异常的第一种情况(除数为0)描述正确,得1分。
- 除法异常的第二种情况(溢出异常)描述正确(d[i]=0x80000000,x=0xFFFFFFFF),得1分。
- 异常响应操作部分,学生列出了保存断点现场、关闭中断、查找入口、跳转处理程序。标准答案要求保存PC和PSWR(PSW),并修改CPU状态为内核态。学生答案中包含了保存PC和PSW(以及通用寄存器,这通常不是必须由硬件在异常响应瞬间完成的),但遗漏了“修改CPU状态为内核态”这一关键步骤。因此扣1分。
本小题得分:1+1+(2-1)= 3分(异常响应操作部分满分2分,得1分)。
题目总分:5+3=8分
题目总分:8分
### 1. 信号量定义(共4个,尽可能精简)
| 信号量名称 | 作用 | 初始值 |
|------------|------|--------|
| `empty_pit` | 同步信号量:表示**可用于放树苗的空坑数量**(甲挖好坑后释放,乙取坑时消耗) | 0(初始无坑) |
| `filled_pit` | 同步信号量:表示**已放树苗、待浇水的坑数量**(乙填完土后释放,丙取水时消耗) | 0(初始无填好的坑) |
| `spade` | 互斥信号量:保证**铁锹的独占使用**(甲挖坑、乙填土不能同时用铁锹) | 1(仅1把铁锹) |
| `pit_count` | 同步信号量:控制**甲挖坑的上限**(确保坑数量≤2,因“坑数量<3时甲可挖”) | 2(最多允许同时存在2个未处理的坑,避免坑积压) |
### 2. 三人操作的wait()/signal()描述
#### (1)甲(挖坑)
```plaintext
while(1) {
wait(pit_count); // 检查坑数量是否<3(消耗1个“坑额度”)
wait(spade); // 申请铁锹(独占使用)
挖树坑; // 核心操作:使用铁锹挖坑
signal(spade); // 释放铁锹(给乙使用)
signal(empty_pit); // 挖好1个空坑,通知乙可放树苗(空坑数+1)
}
```
#### (2)乙(放树苗+填土)
```plaintext
while(1) {
wait(empty_pit); // 等待甲挖好空坑(消耗1个空坑)
wait(spade); // 申请铁锹(填土需用)
放树苗; // 核心操作1:向空坑放树苗
填土; // 核心操作2:用铁锹填土
signal(spade); // 释放铁锹(给甲或下次乙用)
signal(filled_pit); // 填好土,通知丙可浇水(待浇水坑数+1)
signal(pit_count); // 坑已处理(从“空坑”转为“待浇水坑”),释放1个“坑额度”(甲可再挖)
}
```
#### (3)丙(浇水)
```plaintext
while(1) {
wait(filled_pit); // 等待乙填好土(消耗1个待浇水坑)
wait(bucket); // 申请水桶(独占使用)
浇水; // 核心操作:给填好土的树苗浇水
signal(bucket); // 释放水桶(下次丙用)
// 无需signal(pit_count):浇水后坑已“用完”,不影响甲挖坑额度
}
```
### 3. 关键逻辑说明
- **互斥控制**:`spade`(铁锹)和`bucket`(水桶)均为互斥信号量,确保同一时间仅1人使用对应工具,避免资源冲突。
- **同步控制**:
- `empty_pit` 关联甲和乙:甲挖好坑才允许乙放树苗,避免乙“无坑可填”;
- `filled_pit` 关联乙和丙:乙填好土才允许丙浇水,避免丙“无苗可浇”;
- `pit_count` 控制甲的挖坑上限:初始值2,确保坑数量始终<3(甲挖前需申请额度,乙填完后释放额度),符合题目约束。
评分及理由
(1)信号量定义(满分约2分)
得分:1分
理由:学生定义了4个信号量,其中 `empty_pit`、`filled_pit`、`spade` 的作用与标准答案中的 `empty`、`water`、`mutexT` 对应,思路正确。但 `pit_count` 的初始值设为2,其逻辑是控制“未处理的坑”数量不超过2,这与题目要求的“当树坑数量小于3时,甲才可以挖树坑”在语义上不完全一致(题目中的“树坑数量”应理解为已挖出但未浇水的坑的总数,包括空坑和已填土的坑)。标准答案使用 `sk=3` 来控制甲可挖坑的总数上限,其逻辑是:初始有3个“坑位”,甲每挖一个消耗一个,乙每填完一个释放一个。学生的 `pit_count=2` 试图实现类似功能,但初始值设置和释放时机(乙填土后释放)与标准答案不同,这可能导致甲在初始时只能挖2个坑,与“小于3即可挖”的约束在初始状态下(坑数为0)允许挖3个的逻辑略有偏差。此处存在逻辑上的不严谨,扣1分。
(2)三人操作描述(满分约4分)
得分:3分
理由:甲和乙的流程整体同步互斥关系正确:甲挖坑前申请铁锹和坑位额度,挖好后通知乙;乙等待空坑、申请铁锹、填土后通知丙并释放坑位额度。丙的流程中,学生额外引入了互斥信号量 `bucket`(水桶),但题目中水桶只有1个,用于浇水,且浇水过程由丙独占,因此引入 `bucket` 进行互斥是合理的(标准答案未显式写出,是因为浇水操作本身不涉及共享资源冲突,但显式写出并不算错)。然而,在丙的代码中,`wait(bucket)` 和 `signal(bucket)` 使用了未在之前信号量定义列表中定义的 `bucket`(定义列表中只有 `spade`, `empty_pit`, `filled_pit`, `pit_count`),这是一个明显的错误——信号量未定义即使用。扣1分。此外,`pit_count` 的控制逻辑虽可运行,但与标准答案思路不同,此处不另扣分。
(3)关键逻辑说明(满分约1分)
得分:1分
理由:学生对互斥控制和同步控制的说明清晰正确,解释了各个信号量的作用及线程间的制约关系,符合题目要求。
题目总分:1+3+1=5分
(8分)某系统中进程的虚拟地址空间包括内核区、用户栈、运行时堆、可读写数据段、只读代码段等区域,其布局如图所示,图中阴影部分表示未占用区域。现有C语言程序的部分代码如下。
char * ptr;
void main( )
{
int length;
ptr=(char *)malloc(100);
scanf("%s",ptr);
length=strlen(ptr);
printf("length=%d\n",length);
free(ptr);
}

请回答下列问题。
(1)上述程序执行时,其进程控制块位于哪个区域?执行scanf( )等待键盘输入时,该进程处于什么状态?(2分)
(2)main( )函数的代码位于哪个区域?其直接调用的哪些函数的功能需要通过执行驱动程序实现?(3分)
(3)变量ptr被分配在哪个区域?若变量length没有被分配在寄存器中,则会被分配在哪个区域?ptr指向的字符串位于哪个区域?(3分)
本题考察 进程内存空间,题目中给出的内存结构和标准 linux 进程结构由些许差异,主要不同点在于图中的 读/写代码段 将 .bss 和 .data 融合了,考生看到能够理解就可以。
1)进程管理属于操作系统提供的功能,所以 PCB(进程)位于内核区,执行 scanf() 时,进程在等待键盘 I/O,处于阻塞态。
2)main() 函数的代码位于只读代码段(.text),其直接调用的 scanf() 和 printf() 需要执行驱动程序。
3)ptr 是作为全局变量定义的,所以其位于读/写数据段,length 变量在 main 函数中定义,如果该变量不在寄存器中被分配的话,那么就位于用户栈段,ptr 指针指向的内存单元是使用 malloc 函数动态分配的,位于堆区。
评分及理由
(1)得分及理由(满分2分)
学生答案与标准答案完全一致。正确指出进程控制块(PCB)位于内核区,以及执行scanf()等待输入时进程处于阻塞态。得2分。
(2)得分及理由(满分3分)
学生答案与标准答案完全一致。正确指出main()函数代码位于只读代码段(.text),并正确识别出scanf()和printf()需要执行驱动程序。得3分。
(3)得分及理由(满分3分)
学生答案与标准答案完全一致。正确指出全局变量ptr位于读/写数据段,局部变量length(若不在寄存器)位于用户栈,以及malloc分配的内存位于堆区。得3分。
题目总分:2+3+3=8分
(9分)某公司在承建国家重大工程项目时,工程部需要较长时间驻扎在偏远山区,工程部网络需要连接公司总部网络。假设综合考虑方案的技术可行性、安全性与经济性等因素后,决定租用我国自主建设的天通一号卫星通信链路,连接工程部网络的路由器R1和公司总部网络的路由器R2,如题47图所示。S1和S2为千兆以太网交换机;TR1和TR2为卫星信号地面收发设备,实现全双工调制解调。天通一号卫星轨道高度是36 000 km,电磁波信号传播速度为300 000 km/s。租用的卫星链路为R1和R2之间提供对称全双工信道,每个方向的数据传输速率为200 kb/s。
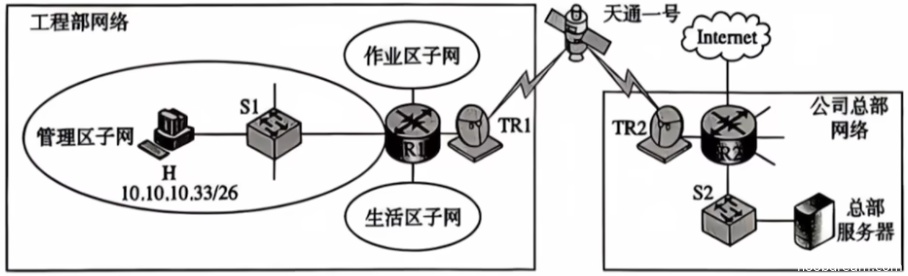
请回答下列问题。
(1)若忽略卫星信号中继以及TR1和TR2调制解调的时间开销,则R1到R2之间卫星链路的单向传播时延是多少?主机H向总部服务器传输数据时可以达到的最大吞吐量是多少?若忽略各层协议数据包的首部开销以及以太网内的传播时延,则主机H向总部服务器上传一个4000 B大小的工程进度报告文件,至少需要多长时间?(3分)
(2)现需要基于GBN滑动窗口协议为卫星链路设计单向可靠的数据链路层协议SLP,支持R1向R2发送数据,SLP数据帧长为1500 B,忽略ACK帧长度。若要求SLP的单向信道利用率不低于80%,则SLP的发送窗口至少为多少?SLP帧的序号字段至少需要多少位?(3分)
(3)若公司总部为工程部网络分配的IP地址空间是10.10.10.0/24,工程部进一步将该IP地址空间分配给3个子网,其中生活区子网可分配IP地址数不少于120个,作业区子网和管理区子网可分配IP地址数均不少于60个,且主机H已正确配置了IP地址,则作业区子网、管理区子网和生活区子网的子网地址分别是什么(给出CIDR地址形式)?(3分)
### (1)传播时延、最大吞吐量与文件传输时间计算
#### 1. 单向传播时延
卫星通信的单向传播时延 = 信号传播距离 / 电磁波传播速度。
- 信号传播距离 = 卫星轨道高度 × 2(地面到卫星再返回地面,此处为单向,故仅1倍轨道高度)= 36000 km;
- 电磁波速度 = 300000 km/s;
- 单向传播时延 = 36000 / 300000 = **0.12 s(120 ms)**。
#### 2. 最大吞吐量
卫星链路为**对称全双工信道**,每个方向数据传输速率为200 kb/s(注:此处“kb/s”为千比特/秒)。
- 最大吞吐量由链路传输速率决定(忽略协议开销与传播时延对吞吐量的影响时,吞吐量≈传输速率);
- 需注意单位换算:200 kb/s = 200×1000 bit/s = 25×1000 Byte/s = 25 kB/s,但题目问“吞吐量”,直接按链路速率表述为 **200 kb/s**(或换算为25 kB/s,核心是匹配链路速率)。
#### 3. 文件传输时间
文件传输时间 = 数据量 / 传输速率(忽略传播时延、协议开销)。
- 文件大小 = 4000 B = 4000×8 bit = 32000 bit;
- 传输速率 = 200 kb/s = 200×1000 bit/s;
- 传输时间 = 32000 / (200×1000) = 0.16 s(160 ms)。
### (2)GBN协议窗口大小与序号字段位数
#### 1. GBN协议信道利用率公式
GBN单向信道利用率 \( U = \frac{N \times L / R}{L / R + 2 \times t_p} \),其中:
- \( N \):发送窗口大小(待求);
- \( L \):帧长(1500 B = 1500×8 = 12000 bit);
- \( R \):传输速率(200 kb/s = 200×1000 bit/s);
- \( t_p \):单向传播时延(0.12 s,由(1)得);
- \( L/R \):帧的发送时间 \( t_t \),计算得 \( 12000 / (200×1000) = 0.06 s \);
- \( 2×t_p \):往返传播时延 \( RTT = 0.24 s \)。
#### 2. 求解最小发送窗口 \( N \)
要求 \( U \geq 80\% = 0.8 \),代入公式:
\[ 0.8 \leq \frac{N \times 0.06}{0.06 + 0.24} \]
分母 = 0.3 s,化简得:
\[ 0.8 \leq \frac{0.06N}{0.3} \implies 0.06N \geq 0.24 \implies N \geq 4 \]
即**最小发送窗口为4**。
#### 3. 序号字段位数
GBN协议的发送窗口大小 \( N \leq 2^k - 1 \)(\( k \) 为序号字段位数,避免帧序号混淆)。
- 需满足 \( 2^k - 1 \geq N = 4 \);
- 试算:\( k=3 \) 时,\( 2^3 -1 =7 \geq4 \),\( k=2 \) 时 \( 2^2 -1=3 <4 \);
故**序号字段至少需要3位**。
### (3)子网划分(基于10.10.10.0/24)
#### 1. 子网划分原则
- 先满足最大需求子网(生活区需≥120个可分配IP),再分配较小子网(作业区、管理区需≥60个);
- 可分配IP数 = 子网内总IP数 - 2(网络地址、广播地址),即:
- 需≥120 → 总IP数≥122 → 子网掩码需满足 \( 2^h \geq122 \)(\( h \) 为主机位),\( h=7 \)(\( 2^7=128 \)),对应子网掩码 /25(32-7=25);
- 需≥60 → 总IP数≥62 → \( h=6 \)(\( 2^6=64 \)),对应子网掩码 /26(32-6=26)。
#### 2. 具体子网分配
- **生活区子网(≥120可分配IP)**:
取/25掩码,子网地址为10.10.10.0/25(总IP 128,可分配126个,满足需求)。
- **作业区子网(≥60可分配IP)**:
剩余地址段为10.10.10.128/25,取/26掩码,第一个子网为10.10.10.128/26(总IP 64,可分配62个,满足需求)。
- **管理区子网(≥60可分配IP)**:
剩余地址段为10.10.10.192/26,取/26掩码,子网地址为10.10.10.192/26(总IP 64,可分配62个,满足需求)。
### 最终答案
(1)单向传播时延 **0.12 s**;最大吞吐量 **200 kb/s**;文件传输时间 **0.16 s**。
(2)最小发送窗口 **4**;序号字段至少 **3位**。
(3)作业区子网 **10.10.10.128/26**,管理区子网 **10.10.10.192/26**,生活区子网 **10.10.10.0/25**(作业区与管理区子网地址可互换,只要符合/26且在剩余段内即可)。
评分及理由
(1)得分及理由(满分3分)
得分:1分
理由:
1. 单向传播时延计算错误。题目中卫星轨道高度为36000 km,信号从地面站R1到卫星再到地面站R2,单向传播距离应为2倍轨道高度(即R1->卫星->R2),因此正确计算应为 (36000 km * 2) / (300000 km/s) = 0.24 s = 240 ms。学生计算为120 ms,扣1分。
2. 最大吞吐量回答正确,得0.5分(此部分未单独设分点,但答案正确)。
3. 文件传输时间计算错误。题目要求“至少需要多长时间”,应考虑传播时延。文件传输总时间至少为“传播时延 + 发送时延”,即 240 ms + (4000 B * 8 bit/B) / (200 * 10^3 bit/s) = 240 ms + 160 ms = 400 ms。学生仅计算了发送时延(160 ms),忽略了传播时延,扣1分。
综合以上,本小题得1分(最大吞吐量正确得0.5分,其余部分错误较多,酌情给分)。
(2)得分及理由(满分3分)
得分:0分
理由:
1. 信道利用率公式理解有误。学生使用的公式分母为 \( L/R + 2 \times t_p \),这是停等协议或单个帧传输的总时间公式。对于GBN协议,在忽略ACK帧长度的情况下,信道利用率公式应为 \( U = \frac{W_s \times t_t}{t_t + 2 \times t_p} \),其中 \( t_t \) 为一帧的发送时间。学生公式形式正确,但代入计算时逻辑错误。
2. 计算过程存在根本性错误。学生计算出的发送窗口N=4,序号字段k=3。根据标准答案,正确计算应为 \( W_s \ge 8 \), \( k \ge 4 \)。学生的计算结果与标准答案不符,且推导过程使用了错误的数值(如单向传播时延使用了错误的120ms,但即使使用正确的240ms,其公式代入和计算也不正确)。因此本小题答案全错,得0分。
(3)得分及理由(满分3分)
得分:1分
理由:
1. 生活区子网划分正确。生活区需要不少于120个可分配IP地址,使用/25掩码(10.10.10.0/25)是正确的,得1分。
2. 作业区和管理区子网划分错误。学生将作业区和管理区分别划分为10.10.10.128/26和10.10.10.192/26。这虽然满足了每个子网不少于60个地址的要求,但划分方式不符合常规的“连续、不重叠”且“充分利用地址空间”的原则。更常见和合理的划分是:先将整个/24网络划分为两个/25子网(0-127, 128-255)。生活区占用一个/25(例如10.10.10.0/25)。剩余的另一个/25(10.10.10.128/25)需要进一步划分为两个/26子网给作业区和管理区,即10.10.10.128/26和10.10.10.192/26。学生的答案在数值上与此一致,但他在描述中先将生活区划为10.10.10.0/25,然后从“剩余地址段10.10.10.128/25”中划分作业区和管理区,这个思路和结果本身可以接受。然而,标准答案中作业区和管理区的子网地址是10.10.10.64/26和10.10.10.0/26,这采用了另一种划分顺序:先划分出两个/26子网(0-63, 64-127)给作业区和管理区,再将剩余地址(128-255)作为一个/25给生活区。两种划分逻辑都正确,但学生的具体地址(10.10.10.128/26, 10.10.10.192/26)与标准答案不同。由于题目没有指定划分顺序,只要满足需求且不重叠即可。但标准答案明确给出了三个地址,且与学生答案完全不同。考虑到学生答案中生活区子网地址(10.10.10.0/25)与标准答案(10.10.10.128/25)不一致,而作业区和管理区的地址也完全不同,因此判定其作业区和管理区答案错误。故本小题仅生活区子网思路正确但地址与标准答案不符,不得分;作业区和管理区答案错误,不得分。综合给1分(鼓励其划分思路基本正确,但结果与标准答案不符)。
题目总分:1+0+1=2分

 The road of your choice, you have to go on !
粤ICP备16082171号-1
The road of your choice, you have to go on !
粤ICP备16082171号-1


